noWorkflow
![]()
Copyright (c) 2016 Universidade Federal Fluminense (UFF). Copyright (c) 2016 Polytechnic Institute of New York University. All rights reserved.
noWorkflow is a tool designed to automatically trace the provenance of a Python script without requiring changes to the original code, thereby providing users with the creation and analysis of a detailed history of how data was produced and transformed. This history ensures transparency and reliability in scientific experiments and data processes. Developed in Python, noWorkflow can capture the provenance of scripts using software engineering techniques such as abstract syntax tree (AST) analysis, reflection, and profiling to collect provenance without necessitating a version control system or any other external environment.
Installing and using noWorkflow is simple and easy. Please check our installation and basic usage guidelines below, and the tutorial videos at our Wiki page.
Team
The main noWorkflow team is composed by researchers from Universidade Federal Fluminense (UFF) in Brazil and New York University (NYU), in the USA.
- João Felipe Pimentel (UFF) (main developer)
- Juliana Freire (NYU)
- Leonardo Murta (UFF)
- Vanessa Braganholo (UFF)
- Arthur Paiva (UFF)
Collaborators
- David Koop (University of Massachusetts Dartmouth)
- Fernando Chirigati (NYU)
- Paolo Missier (Newcastle University)
- Vynicius Pontes (UFF)
- Henrique Linhares (UFF)
- Eduardo Jandre (UFF)
- Jessé Lima (Summer of Reproducibility)
- Joshua Daniel Talahatu (Google Summer of Code)
History
The project started in 2013, when Leonardo Murta and Vanessa Braganholo were visiting professors at New York University (NYU) with Juliana Freire. At that moment, David Koop and Fernando Chirigati also joined the project. They published the initial paper about noWorkflow in IPAW 2014. After going back to their home university, Universidade Federal Fluminense (UFF), Leonardo and Vanessa invited João Felipe Pimentel to join the project in 2014 for his PhD. João, Juliana, Leonardo and Vanessa integrated noWorkflow and IPython and published a paper about it in TaPP 2015. They also worked on provenance versioning and fine-grained provenance collection and published papers in IPAW 2016. During the same time, David, João, Leonardo and Vanessa worked with the YesWorkflow team on an integration between noWorkflow & YesWorkflow and published a demo in IPAW 2016. The research and development on noWorkflow continues and is currently under the responsibility of João Felipe, in the context of his PhD thesis.

Publications
- MURTA, L. G. P.; BRAGANHOLO, V.; CHIRIGATI, F. S.; KOOP, D.; FREIRE, J.; [noWorkflow: Capturing and Analyzing Provenance of Scripts.] (https://github.com/gems-uff/noworkflow/raw/master/docs/ipaw2014.pdf) In: International Provenance and Annotation Workshop (IPAW), 2014, Cologne, Germany.
- PIMENTEL, J. F. N.; FREIRE, J.; MURTA, L. G. P.; BRAGANHOLO, V.; Collecting and Analyzing Provenance on Interactive Notebooks: when IPython meets noWorkflow. In: Theory and Practice of Provenance (TaPP), 2015, Edinburgh, Scotland.
- PIMENTEL, J. F.; FREIRE, J.; BRAGANHOLO, V.; MURTA, L. G. P.; Tracking and Analyzing the Evolution of Provenance from Scripts. In: International Provenance and Annotation Workshop (IPAW), 2016, McLean, Virginia.
- PIMENTEL, J. F.; FREIRE, J.; MURTA, L. G. P.; BRAGANHOLO, V.; Fine-grained Provenance Collection over Scripts Through Program Slicing. In: International Provenance and Annotation Workshop (IPAW), 2016, McLean, Virginia.
- PIMENTEL, J. F.; DEY, S.; MCPHILLIPS, T.; BELHAJJAME, K.; KOOP, D.; MURTA, L. G. P.; BRAGANHOLO, V.; LUDÄSCHER B.; Yin & Yang: Demonstrating Complementary Provenance from noWorkflow & YesWorkflow. In: International Provenance and Annotation Workshop (IPAW), 2016, McLean, Virginia.
- PIMENTEL, J. F.; MURTA, L. G. P.; BRAGANHOLO, V.; FREIRE, J.; noWorkflow: a Tool for Collecting, Analyzing, and Managing Provenance from Python Scripts. In: International Conference on Very Large Data Bases (VLDB), 2017, Munich, Germany.
- PONTES, V.: Reducing the Storage Overhead of the noWorkflow Content Database by using Git. Final undergraduate Project, Sistemas de Informação, Universidade Federal Fluminense, 2018.
- OLIVEIRA, E.; Enabling Collaboration in Scientific Experiments. Masters Dissertation, Universidade Federal Fluminense, 2022.
Quick Installation
To install noWorkflow, you should follow these basic instructions. Note that these steps may install an older version of noWorkflow. To make sure you are using the newest stable version, please follow the “Alternative” installation procedure mentioned below.
Using Python 3.8, use pip to install noWorkflow:
$ pip install noworkflow[all]
This installs noWorkflow, PyPosAST, SQLAlchemy, python-future, flask, IPython, Jupyter and PySWIP. The only requirements for running noWorkflow are PyPosAST, SQLAlchemy and python-future. The other libraries are only used for provenance analysis.
If you only want to install noWorkflow, PyPosAST, SQLAlchemy and python-future please do:
$ pip install noworkflow
Alternative: install the most up-to-date version of noWorkflow ——————
If you wish to install the most up-to-date stable version of noWorkflow, you can clone our repository using Git.
$ git clone git@github.com:gems-uff/noworkflow.git
If you don’t have git, just download the ZIP source code from our repository and decompress the zip file into a folder.
Then, use Python to install it (the most up-to-date version of noWorkflow works with newer versions of Python. The current version was tested with Python 3.12.4.
Go to the folder where you decompressed the files (or where you cloned the project) and then execute the following:
$ cd noworkflow-master
$ python setup.py install
$ pip install -e ".[all]"
This installs noWorkflow and its dependencies on your system.
Upgrade
To upgrade the version of a previously installed noWorkflow using pip, you should run the following command:
$ pip install --upgrade noworkflow[all]
Basic Usage
noWorkflow is transparent in the sense that it requires neither changes to the script, nor any laborious configuration. Run
$ now --help
to learn the usage options.
noWorkflow comes with a demonstration project. Follow the Wiki page to see how extract it.
To run noWorkflow you should run:
$ now run script.py
The -v option turns the verbose mode on, so that noWorkflow gives you feedback on the steps taken by the tool. The output, in this case, is similar to what follows.
$ now run -v script.py
[now] removing noWorkflow boilerplate
[now] setting up local provenance store
[now] using content engine noworkflow.now.persistence.content.plain_engine.PlainEngine
[now] collecting deployment provenance
[now] registering environment attributes
[now] collection definition and execution provenance
[now] executing the script
[now] the execution of trial 91f4fdc7-6c36-4c9d-a43a-341eaee9b7fb finished successfully
Each new run produces a different trial that will be stored with a universally unique identifier in the relational database.
Verifying the module dependencies is a time consuming step, and scientists can bypass this step by using the -b flag if they know that no library or source code has changed. The current trial then inherits the module dependencies of the previous one. To see more usage options, run “now run -h”.
To restore files, run:
$ now restore [trial]
By default, the restore command will restore the trial script, imported local modules and the first access to files. Use the option -s to leave out the script; the option -l to leave out modules; and the option -a to leave out file accesses. The restore command track the evolution history. By default, subsequent trials are based on the previous Trial. When you restore a Trial, the next Trial will be based on the restored Trial.
The restore command also provides a -f path option. This option can be used to restore a single file. With this command there are extra options: -t path2 specifies the target of restored file; -i id identifies the file. There are 3 possibilities to identify files: by access time, by code hash, or by number of access. The option -f does not affect evolution history. To see more usage options, run “now restore -h”.
To execute the git garbage collection in the content database, run:
$ now gc
Analysis
To list all trials, just run:
$ now list
Assuming we run the experiment again and then run now list, the output would be as follows.
$ now list
[now] trials available in the provenance store:
[f]Trial 7fb4ca3d-8046-46cf-9c54-54923d2076ba: run -v .\simulation.py .\data1.dat .\data2.dat
with code hash 6a28e58e34bbff0facaf55f80313ab2fd2505a58
ran from 2023-04-12 19:38:50.234485 to 2023-04-12 19:38:51.672300
duration: 0:00:01.437815
[*]Trial 01482b72-2005-4319-bd57-773291f9f7b1: run -v .\simulation.py .\data1.dat .\data2.dat
with code hash 6a28e58e34bbff0facaf55f80313ab2fd2505a58
ran from 2023-04-12 19:40:18.747749 to 2023-04-12 19:40:48.401719
duration: 0:00:29.653970
[b]Trial 8bf59cf5-cd06-409e-97f6-185063b1cfc3: restore 3
with code hash c3aeb4cb9af363b375aec603010dd1b97460f6b1
ran from 2023-04-12 19:45:36.937565 to 2023-04-12 19:45:37.141808
duration: 0:00:00.204243
Each symbol between brackets is its respective trial status. They can express if:
a trial has not finished: f
a trial has finished: *
a trial is a backup: b
To look at details of an specific trial, use:
$ now show [trial]
This command has several options, such as -m to show module dependencies; -d to show function definitions; -e to show the environment context; -a to show function activations; -p to show noworkflow parameters; and -f to show file accesses.To see more usage options, please run “now show -h”.
To compare two trials:
$ now diff [trial1] [trial2]
where [trial1] and [trial2] are the trial ids to be compared. It has options to compare modules (-m), environment (-e), file accesses (-f). It has also an option to present a brief diff, instead of a full diff (–brief). To see more optional arguments, run “now diff -h”.
The dataflow option exports fine-grained provenance data to a graphviz dot representing the dataflow. This command has many options to change the resulting graph. Please, run “now dataflow -h” to get their descriptions.
$ now dataflow [trial] -m prospective | dot -Tpng -o prospective.png
To export provenance data of a given trial to Prolog facts, so inference queries can be run over the database, run:
$ now export [trial]
It also exports inference rules by -r argument.
To export the collected provenance of a trial to Prov.
$ now prov [trial]
The schema option presents the SQL schema of noWorkflow:
$ now schema sql
or Prolog schema of noWorkflow:
$ now schema prolog
Adding the -d optional argument exports graphic schema to a dot format.
To check a textual history evolution graph of trials, run:
$ now history [trial]
The evaluation option query evaluation and its dependencies. The evaluation command can be used without arguments, and the default option is display. The argument shows evaluations that represent executions or accesses to values and expressions in the code, capturing the interaction between variables, functions, objects, and other script elements.
$ now evaluation
The argument wdf identifies and displays dependency relationships between code elements, tracing how data, functions, and variables have been derived from each other.
$ now evaluation wdf
The ast option exports the collected provenance of a trial to Prolog or Notebook.
$ now ast [trial]
Visualization Tool
The visualization tool requires Flask to be installed. To install Flask, you can run:
$ pip install flask==2.1.3
The vis option starts a visualization tool that allows interactive analysis:
$ now vis -b
The visualization tool shows the evolution history, the trial information, an activation graph. It is also possible to compare different trials in the visualization tool. An activation graph can be changed into definition graph that visualizes the structure of a trial, showing the hierarchical relationships of code constructs.
Explore this tutorial to master the Visualization Tool
Collaboration Usage
noWorkflow can also be used to run collaborative experiments. Scientists with different computers can work on the same experiments without much trouble. To do this they must do push and pull operations to a server.
The server can be a central one or a peer-to-peer connection. To set up a server or connection online the command below must be run
$ now vis --force true
The ast option generates the Abstract Syntax Tree (AST) for a given trial. By default, it outputs the AST in its standard format. However, you can specify the output format using the -j (–json) option for JSON format or the -d (–dot) option for Graphviz dot format.
$ now ast 08ece614-f5ae-4e65-93a0-5a8b44ac9a44 --dot
The command line output will show the server address
* Serving Flask app 'noworkflow.now.vis.views'
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on http://localhost:5000
Press CTRL+C to quit
In the case above it’s http://localhost:5000
To create a new experiment you must open the server address and choose the “Add Experiment” option

Then you must give the experiment a name, write its description, and choose “Confirm”

If the experiment is successfully created you should see a message stating so
 As you can see in the image above, an id and an url for the experiment will be generated after the experiment is created.
The url is extremely important since it will be used to do the push and pull operations.
As you can see in the image above, an id and an url for the experiment will be generated after the experiment is created.
The url is extremely important since it will be used to do the push and pull operations.
To get the experiment on a computer you first need to navigate to the folder where you want the experiment, then execute the pull command. The pull command accepts a –url parameter that must be followed by the experiment’s url. For example
$ now pull --url http://localhost:5000/experiments/958273cc-b90a-4d1c-b617-43bd2dca20de
The command will download the experiment’s files and provenience in the folder. If there are already any files or trials in the experiment you must execute the command “now restore” with or without a trial id.
To push(or commit) to the server(or peer-to-peer connection) you must run the push command. The push command accepts a –url parameter that must be followed by the experiment’s url. For example
$ now push --url http://localhost:5000/experiments/958273cc-b90a-4d1c-b617-43bd2dca20de
You can also add groups to a server by navigating to the “Group Information” tab and choosing the “Add Group” option

Then you should write the group’s name and choose “Confirm”

If the group is added successfully, you should see a message confirming that the group was created. You should also see the options to add a user to a group or to delete the group

If the option to add a user is chosen, you must select the user from a list and choose “Confirm”.

To delete a group just select “Delete Group”, then “OK” on the alert that will appear on the screen

Annotations
You can also add annotations to an experiment. To do this you need to access the experiment’s url, then go to the “Annotation” tab, and select “Add Annotation”

After filling the annotation’s information, choose “Confirm”
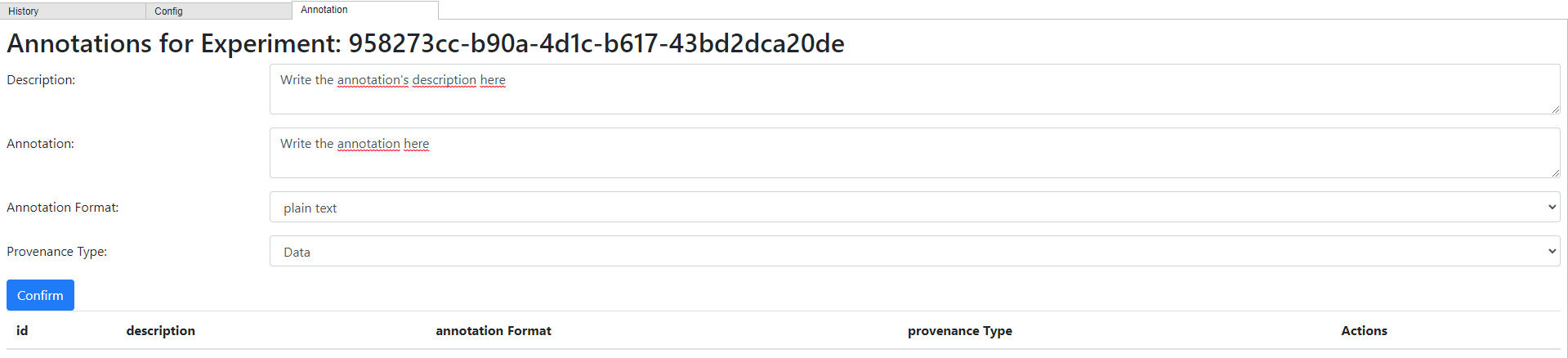
If the annotation is added, you will see a success message and will be able to download the annotation as seen below

Annotations can also be added to a trial by following the same procedure above. But first, you must select a trial, choose “Manage Annotations”
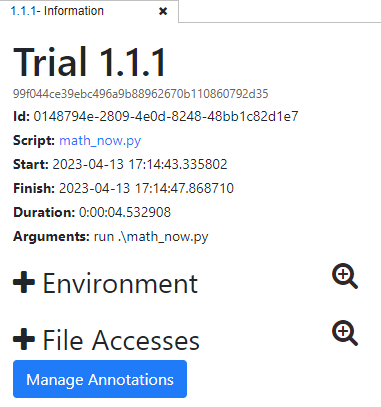
IPython Interface
Another way to run, visualize, and query trials is to use Jupyter notebook with IPython kernel. To install Jupyter and noworkflow extension, you can run
$ pip install jupyter
$ pip install noworkflow_labextension
Notes:
-
It is possible to run many of the commands below without installing
noworkflow_labextension. This package enables visualizing trials and history in the notebook. -
This visualization package supports Jupyter Lab and Notebook 7+. The support for older versions of notebook has been dropped.
After installing jupyter (and noWorkflow labextension), go to the project directory and execute:
$ jupyter notebook
It will start a local webserver where you can create notebooks and run python code.
Before loading anything related to noworkflow on a notebook, you must initialize it:
In [1]: %load_ext noworkflow
...: import noworkflow.now.ipython as nip
It is equivalent to:
In [1]: %load_ext noworkflow
...: nip = %now_ip
After that, you can either run a new trial or load an existing object (History, Trial, Diff).
There are two ways to run a new trial:
1- Load an external file
In [1]: arg1 = "data1.dat"
arg2 = "data2.dat"
In [2]: trial = %now_run simulation.py {arg1} {arg2}
...: trial
Out [2]: <Trial "7fb4ca3d-8046-46cf-9c54-54923d2076ba"> # Loads the trial object represented as a graph
2- Load the code inside a cell
In [3]: arg = 4
In [4]: %%now_run --name new_simularion --interactive
...: l = range(arg)
...: c = sum(l)
...: print(c)
6
Out [4]: <Trial "01482b72-2005-4319-bd57-773291f9f7b1"> # Loads the trial object represented as a graph
In [5]: c
Out [5]: 6
Both modes supports all the now run parameters.
The –interactive mode allows the cell to share variables with the notebook.
Loading existing trials, histories and diffs:
In [6]: trial = nip.Trial("7fb4ca3d-8046-46cf-9c54-54923d2076ba") # Loads trial with Id = 7fb4ca3d-8046-46cf-9c54-54923d2076ba
...: trial # Shows trial graph
Out [6]: <Trial 7fb4ca3d-8046-46cf-9c54-54923d2076ba>
In [7]: history = nip.History() # Loads history
...: history # Shows history graph
Out [7]: <History>
In [8]: diff = nip.Diff("7fb4ca3d-8046-46cf-9c54-54923d2076ba", "01482b72-2005-4319-bd57-773291f9f7b1") # Loads diff between trial 7fb4ca3d-8046-46cf-9c54-54923d2076ba and 01482b72-2005-4319-bd57-773291f9f7b1
...: diff # Shows diff graph
Out [8]: <Diff "7fb4ca3d-8046-46cf-9c54-54923d2076ba" "01482b72-2005-4319-bd57-773291f9f7b1">
To visualize the dataflow of a trial, it is possible to use the dot attribute of trial objects:
In [9]: trial.dot
Out [9]: <png image>
This command requires an installation of graphviz.
There are attributes on those objects to change the graph visualization, width, height and filter values. Please, check the documentation by running the following code on jupyter notebook:
```python
In [10]: trial?
In [11]: history?
It is also possible to run prolog queries on IPython notebook. To do so, you will need to install SWI-Prolog with shared libraries and the pyswip module.
You can install pyswip module with the command:
$ pip install pyswip-alt
Check how to install SWI-Prolog with shared libraries at https://github.com/yuce/pyswip/blob/master/INSTALL
To query a specific trial, you can do:
In [12]: result = trial.query("activation(_, 550, X, _, _, _)")
...: next(result) # The result is a generator
Out [12]: {'X': 'range'}
To check the existing rules, please do:
In [13]: %now_schema prolog -t
Out [13]: [...]
Finally, it is possible to run the CLI commands inside ipython notebook:
In [14]: !now export {trial.id}
Out [14]: %
...: % FACT: activation(trial_id, id, name, start, finish, caller_activation_id).
...: %
...: ...
To clean Jupyter Notebook using the collected provenance, run:
$ now clean [trial]
Contributing
Pull requests for bugfixes and new features are welcome!
For installing the python dependencies locally, clone the repository and run:
pip install -e noworkflow/capture
For changes on the now vis or IPython integration files, install nodejs, Python 3 and run:
cd noworkflow/npm
python watch.py
(If it is your first time making changes or if you changed some modules, you must first run the following command before “python watch.py”:)
npm install
Included Software
Parts of the following software were used by noWorkflow directly or in an adapted form:
The Python Debugger
Copyright (c) 2001-2016 Python Software Foundation.
All Rights Reserved.
Acknowledgements
We would like to thank CNPq, FAPERJ, and the National Science Foundation (CNS-1229185, CNS-1153503, IIS-1142013) for partially supporting this work.
License Terms
The MIT License (MIT)
Copyright (c) 2013 Universidade Federal Fluminense (UFF), Polytechnic Institute of New York University.
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.